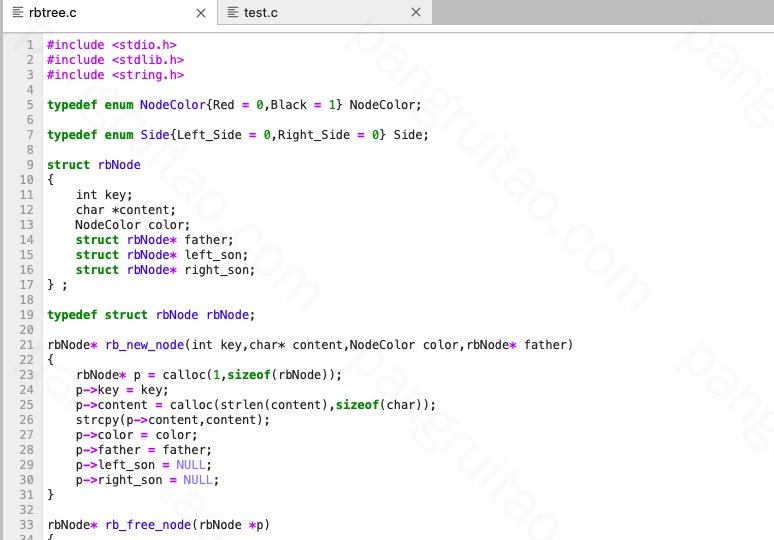
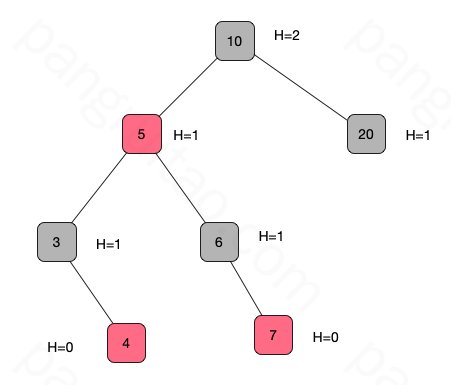
算法


二叉树遍历和用遍历结果确定二叉树
1.前序遍历 定义 对任意子树,优先访问根节点,再左子树,再右子树。 遍历 遍历时需使用栈保存根节点,用以未来 … 阅读更多
数据结构重点-学习笔记
1. 基本概念 数据的逻辑结构 与存储无关的数据逻辑关系,仅对外业务逻辑关心。 如线性结构、一般线性表(有序表 … 阅读更多
A Sharing Notebook
1.前序遍历 定义 对任意子树,优先访问根节点,再左子树,再右子树。 遍历 遍历时需使用栈保存根节点,用以未来 … 阅读更多
1. 基本概念 数据的逻辑结构 与存储无关的数据逻辑关系,仅对外业务逻辑关心。 如线性结构、一般线性表(有序表 … 阅读更多