1. 内容

大家好,我是PPDM组的PP。
不过由于DM没来,这次比赛其实我这组只有PP。
我先给大家简单介绍一下Demo。
我做的东西比较简单,想要的效果也很简单,那就是让人们可以用耳朵来看。
一旦做好了,我们可以为盲人提供一片珍贵的视野,同时也能为我们自己带来一些新鲜有趣的体验。

Demo中,做了一个简单的可视化,背景是 TOF 的深度信息,越近越亮,越远越黑。在中部,我设置了24个区域,从左到右每一块区域对应钢琴的一个琴键,音频从左到右由低到高。
当区域检测到物体距离信息之后,根据距离远近,弹出相应的音,物体越近弹得越重,物体越远,弹得越轻。
再略加了一点固定节奏,同时控制不出现不和谐因,优先出现常见和弦等等,让整体感觉好听一些。
通过这种方式将TOF得到的部分空间信息,变成了音乐。
比如面前有人从左到右走动,将大致听到由低音到高音的一段旋律。
有人逐渐接近,将听到由轻变强的一段旋律。
但是!

看个串串。刚说好的用耳朵看呢?确定这真能提供视觉?
别急,我先简要介绍一些神经心理学方面的有趣知识,这些构成这次的想法的来源兼理论基础。
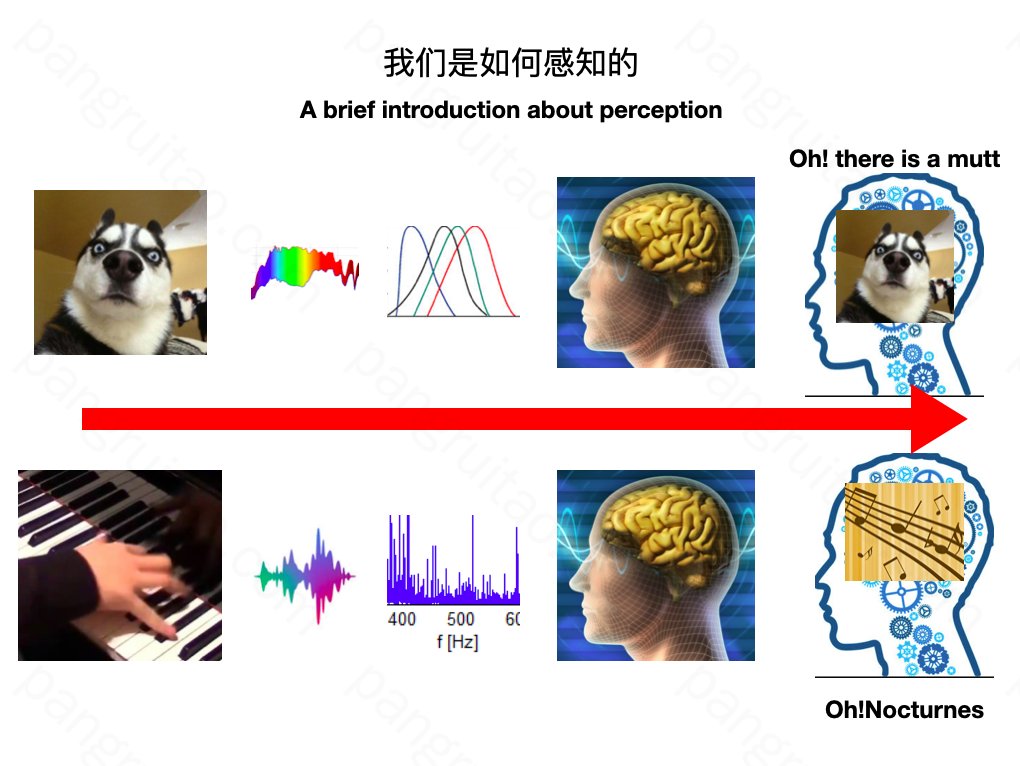
主要谈谈我们的感知方式。应该很多人也都清楚,就简要说一下。
比如一只傻狗在我们面前。我们怎么感知到面前有只傻狗的呢?
首先是他体表会反射出大量光子。
对于眼睛中的每一个点或像素,获得的通常都是个连续的光谱,这里仅截了可见光部分。人眼通过RGB三种视锥细胞和视杆细胞各自对其进行采样,以神经冲动电信号方式,传给大脑。大脑再经过神经网络奇葩的运算,最后才认知到,嗯,面前有一条傻狗。
而听歌呢,也类似,琴键按下后,发出声波,耳朵里有很多毛细胞,每种毛细胞对不同的音频比较敏感,进而分频采样。这里图找错了,他们的频率分布是呈指数增长的。这些细胞也将通过电信号的方式告知大脑,大脑处理后认知到这是什么什么音,进一步知道是什么曲子等等。
这个过程有挺多有意思的细节。但我觉得最有意思的是大脑处理这部分。

我们的脑回路非常混乱,以至于很多处理过程非常难以追踪和理解,这也是神经学家反编译大脑的进展非常缓慢或困难的原因之一。
”看着好香“、”听着好痛“、”闻着好酸“都或多或少体现了一些这种交叉混乱性。
但这种混乱的同时又展现出了一种强大的灵活性,体现在通过刻意训练或者强化学习,我们可以比较容易地改变我们脑回路
进而有目的地让其扭曲,弯折,甚至可以把两种感受交叉起来认知。
这样说还有点抽象,举些例子

我们可以颠倒我们的视野,再一段时间之后,大脑会帮助我们把这颠倒的世界转回来,让自己都不再能意识到,面前一切被颠倒过。

奥地利一个神经学家曾经就做过这么一个视野上下颠倒的实验,还有纪录片。
他让学生带上特殊的眼镜,眼镜通过三次反光使面前视野上下颠倒。
一开始,得扶着学生走路。并且尝试用木棍戳学生的时候,学生将挡板举向了错误的方向。
但是,只经过7天左右的适应,学生已经完全感觉不到视野有问题了,骑自行车也不会有问题。
最后,后来将眼镜取下来,学生又感觉自己视野被颠倒了,花了几天才重新颠倒回来。
充分证明大脑的灵活和可塑性,虽然强化学习这个过程需要一些时间。
然而,除了这些实验,还有一些我们更熟悉的例子。
也比如眼镜产生的视野形变,特别是镜片边缘。特别是我们第一次戴眼镜的时候,这种形变产生的不适,晕眩感可能非常明显。
这时,如果去打羽毛球的话,大概率会接不到球。
不过适应一段时间后就没问题了。甚至长期佩戴眼镜后,不刻意去看都会忘了有形变这回事。
这也是归功于大脑的学习能力或者可塑性。
使眼镜扭曲光线,但扭曲不了我们的心灵。

当然了,如果一定想扭曲我们的心灵,也是没问题的。
只要在大脑学习的时候输入一些错误的信息。
这是知乎上找到的一个移魂换体的实验介绍。
实验中,为被试展示一个假手,同时将真手用挡板挡住。之后为假手和真手同步施加刺激,比如拿毛刷去刷。被试会产生错觉,潜意识慢慢相信假手就是自己的。
这时用一把刀或锤子去准备砸假手,人脑产生的反应和真手快背伤害时几乎一样。
这张图就是被试被吓得大叫并且缩手的一张截图。
如果不刺激手,直接刺激大脑皮层对应位置,也可以达到相同效果。
这张是类似的另外一个实验。被试带上VR眼睛,用这个小假人的视角,同步加上刺激。最终将会认同自己就是这个小人,并且忘了正常的自己才是自己,表现在用刀去威胁真正的自己时,自己透过VR眼镜看着,大脑却没有一丝慌张,以为那是别人

okay,分享一下那些实例,除了本身比较有趣,主要还是想说明大脑的灵活和可塑性。
基于这样的可塑性,我们也可以做些正事。
比如对于盲人,也许是眼睛这里有问题,无法感应外界的光。那这条通路就断了。
怎么办呢?我们可以通过一些手段,将外界的视觉相关的信息包装成其他形式的信息,通过其他通路,经过一段时间大脑适应,也理应可以让人产生视觉。
其实对于这样的方式已经有一些研究探索了
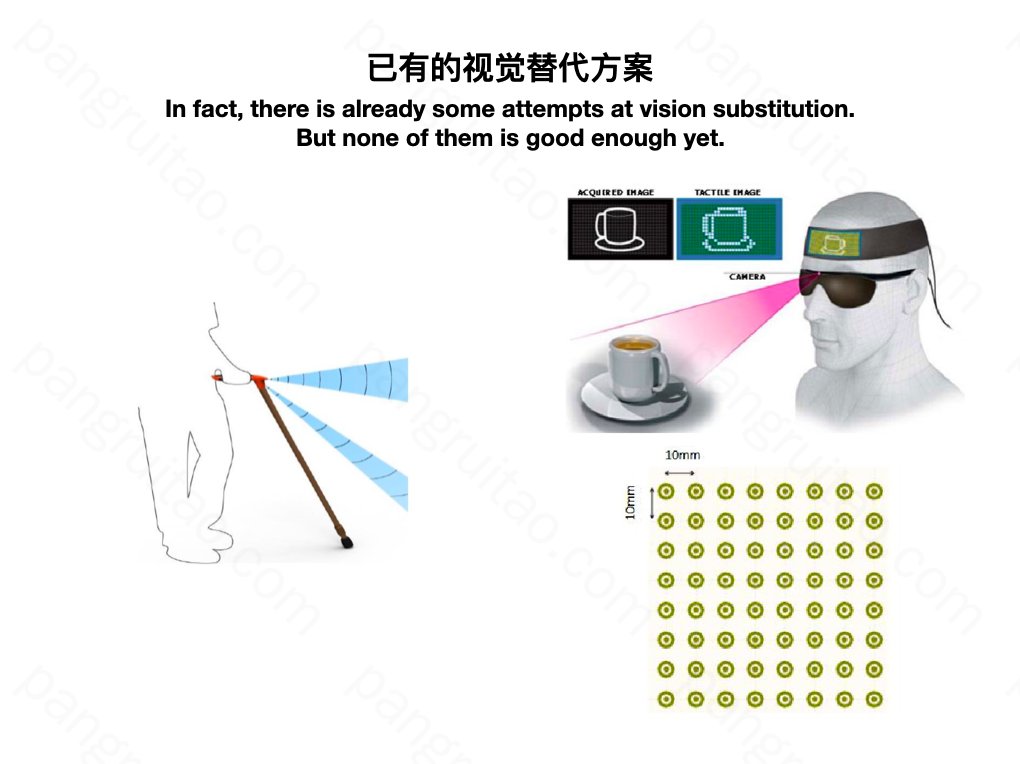
这是知网上找的的几篇论文里面相关介绍的截图,大部分是10年以前的。
左边这种是用超声波测距。通过振动进行反馈,越近振动越强。昨天做PPT的时候搜了一下,淘宝上还有卖的。
右边这种是通过图像边缘识别,用电极矩阵给人皮肤传达信号。
大部分论文都是用的右边这种,并尝试身体各个不同的地方,如肚子,舌头,手臂等等。
但这两种方式都有明显的局限性。
左边振动信息太单一,和视觉的丰富度相去甚远。
右边这种用的是电极。如果电压太低,会没有感觉,分辨不清。电压太高呢,头皮发麻。

所以,我有了这么一个想法和 Demo。
为什么要选择 TOF 呢?已有解决方案都用的图像识别模式。
事实上图像信息虽然重要,但对多数动物来说,深度信息可能更重要。
你看蝙蝠,有眼睛也要装个雷达去测距。
再比如猫狗牛羊颜色视觉一两种,很单薄,视力通常也不怎么样,但也会不遗余力地长两只眼睛去测距。
足可见深度信息对于感知的重要性。
所以我觉得 TOF 等高密度的深度监测技术,有可能为这个领域提供新的发展可能性。
因此这次也尝试以 TOF 作为信息输入。又因为手机不好做电极,电极表现也没有音乐那么优雅。
所以有了这么一个听觉-深度信息视觉的方案尝试。
最后讲一讲,这种功能的应用场景和对应的市场空间。

首先是一直提到的盲人市场。
不过现在来看,要效果好,还需要挺多优化和尝试。
第一,需要更广角的 TOF
第二,可以尝试加更多的乐器,对应空间不同的区域,更多的信息,同时还能听交响乐。
第三,需要更便携,面向盲人,手机的大部分组件是可以不要的,可以改成眼镜、手环、项链等等形式的设备。
第四,如果效果很好,也可以尝试 TOF 和电极矩阵的组合。
除此之外
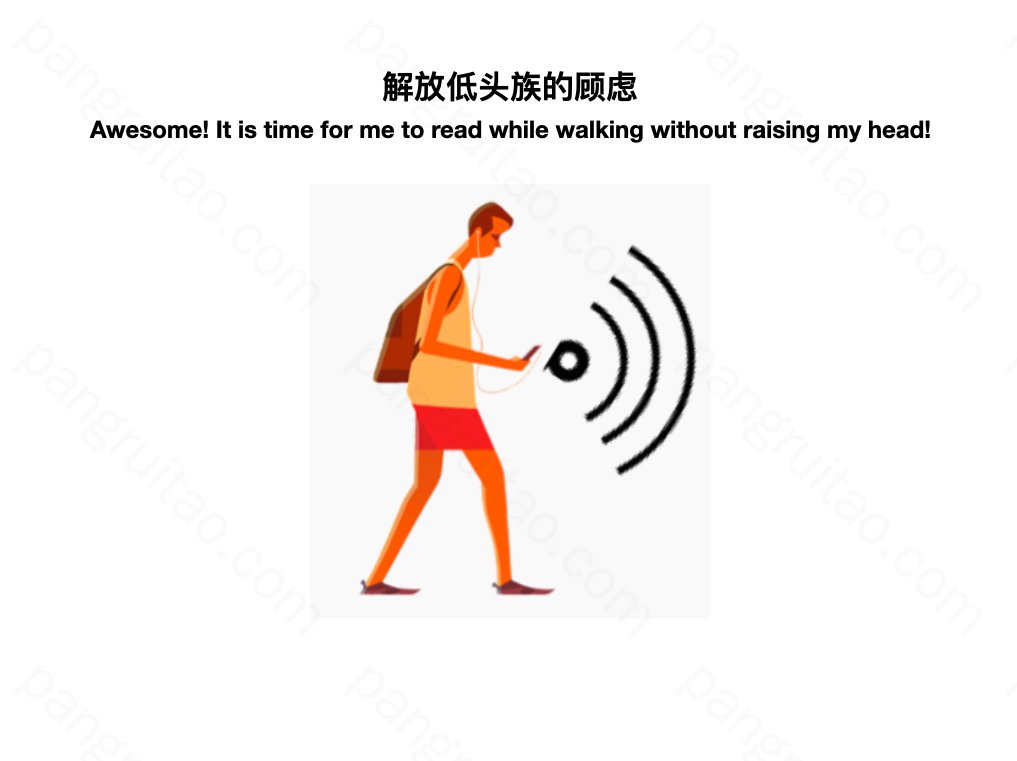
还可以为低头族探距。
我们走在一些熟悉又安全的路上时,用眼睛看路是对低头族来说是一种严重的资源浪费。
这个时候如果能用耳朵看路,就能解放脖子和眼睛,悠悠哒哒看小说,多好。

最后,是我个人最偏好的一种方向。
我们人的感受器其实也很局限,大部分只能接受很局限的信息。
你看那光谱,它那么长,我们却只能看到其中一小段。对这一小段里面还只能有采样三种颜色。
很多鸟儿都是四个颜色。
这意味着同样一张图,我们看起来可能是纯色,啥都没有,鸟就能看出这是一个害羞男孩子的情书。
同样,正如臭豆腐闻着臭,吃着香。
有些人,比如黄渤,比如我,看着不好看。
但说不定好听啊!

谢谢大家
按您的教程做了个wordpress,但是主页没有安装界面,只有个index of,方便的话麻烦指导一下,微信:19906365856
好